云原生
Kubernetes基础
容器技术介绍
Docker快速入门
Containerd快速入门
K8S主要资源罗列
认识YAML
API资源对象
Kubernetes安全掌控
Kubernetes网络
Kubernetes高级调度
Kubernetes 存储
Kubernetes集群维护
Skywalking全链路监控
ConfigMap&Secret场景应用
Kubernetes基础概念及核心组件
水平自动扩容和缩容HPA
Jenkins
k8s中部署jenkins并利用master-slave模式实现CICD
Jenkins构建过程中常见问题排查与解决
Jenkins部署在k8s集群之外使用动态slave模式
Jenkins基于Helm的应用发布
Jenkins Pipeline语法
EFKStack
EFK日志平台部署管理
海量数据下的EFK架构优化升级
基于Loki的日志收集系统
Ingress
基于Kubernetes的Ingress-Nginx解决方案
Ingress-Nginx高级配置
使用 Ingress-Nginx 进行灰度(金丝雀)发布
Ingress-nginx优化配置
APM
Skywalking全链路监控
基于Helm部署Skywalking
应用接入Skywalking
服务网格
Istio
基于Istio的微服务可观察性
基于Istio的微服务Gateway实战
Kubernetes高可用集群部署
Kuberntes部署MetalLB负载均衡器
Ceph
使用cephadm部署ceph集群
使用Rook部署Ceph存储集群
openstack
glance上传镜像失败
mariadb运行不起来
创建域和项目错误_1
创建域和项目错误_2
安装计算节点
时钟源
网络创建失败
本文档使用 MrDoc 发布
-
+
首页
Kubernetes网络
# 1、Pod网络 在K8S集群里,多个节点上的Pod相互通信,要通过网络插件来完成,比如Calico网络插件。 使用kubeadm初始化K8S集群时,有指定一个参数--pod-network-cidr=10.18.0.0/16 它用来定义Pod的网段。 而我们在配置Calico的时候,同样也有定义一个CALICO_IPV4POOL_CIDR的参数,它的值同样也是Pod的网段。 容器网络尤其是在跨主机容器间的网络是非常复杂的。目前主流的容器网络模型主要有Docker公司提出的Container Network Model(CNM)模型和CoreOS公司提出的Container Network Interface(CNI)模型,而Kubernetes采用了由CoreOS公司提出的CNI模型。 - 1)CNI 首先我们介绍一下什么是 CNI,它的全称是 Container Network Interface,即容器网络的 API 接口。 CNI本身并不能提供网络服务,它只是定义了对容器网络进行操作和配置的规范。CNI仅关注在创建容器时分配网络资源,和在销毁容器时删除网络资源,这使得CNI规范非常轻巧、易于实现,得到了广泛的支持。 而真正实现和落地这些规范的是CNI插件。常见的CNI插件包括Calico、flannel、Terway、Weave Net 以及 Contiv。 - 2)K8S如何使用CNI插件 K8s 通过 CNI 配置文件来决定使用什么 CNI。 基本的使用方法为: - 首先在每个节点上配置 CNI 配置文件(/etc/cni/net.d/xxnet.conf),其中 xxnet.conf 是某一个网络配置文件的名称;  - 安装 CNI 配置文件中所对应的二进制插件;  - 在这个节点上创建 Pod 之后,Kubelet 就会根据 CNI 配置文件执行前两步所安装的 CNI 插件; 具体的流程如下图所示: 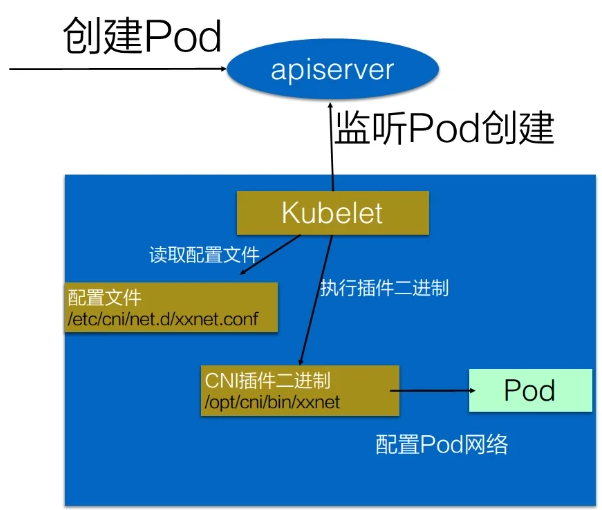 在集群里面创建一个 Pod 的时候,首先会通过 apiserver 将 Pod 的配置写入。apiserver 的一些管控组件(比如 Scheduler)会调度到某个具体的节点上去。Kubelet 监听到这个 Pod 的创建之后,会在本地进行一些创建的操作。当执行到创建网络这一步骤时,它首先会读取刚才我们所说的配置目录中的配置文件,配置文件里面会声明所使用的是哪一个插件,然后去执行具体的 CNI 插件的二进制文件,再由 CNI 插件进入 Pod 的网络空间去配置 Pod 的网络。配置完成之后,Kuberlet 也就完成了整个 Pod 的创建过程,这个 Pod 就在线了。 - 3)基于Calico的Pod网络 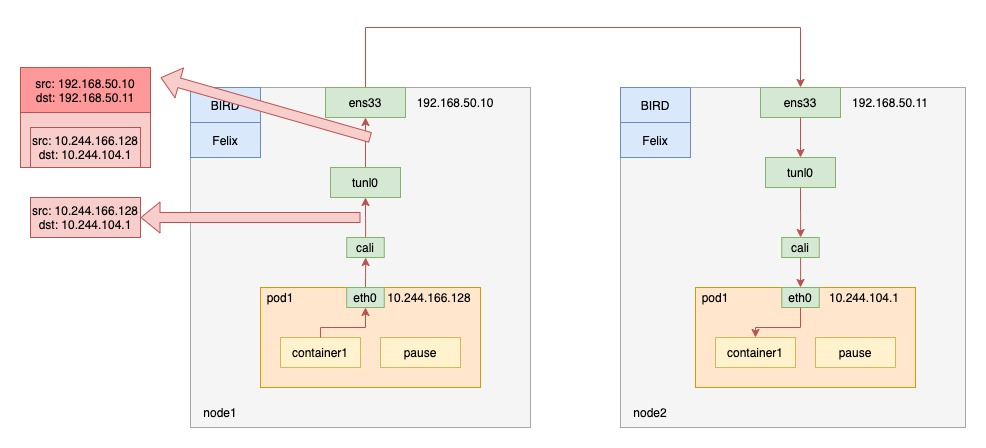 tunl0会将容器的源IP和目标IP进行封装,当数据包到达ens33时又会将宿主机的源IP和目标IP进行封装。 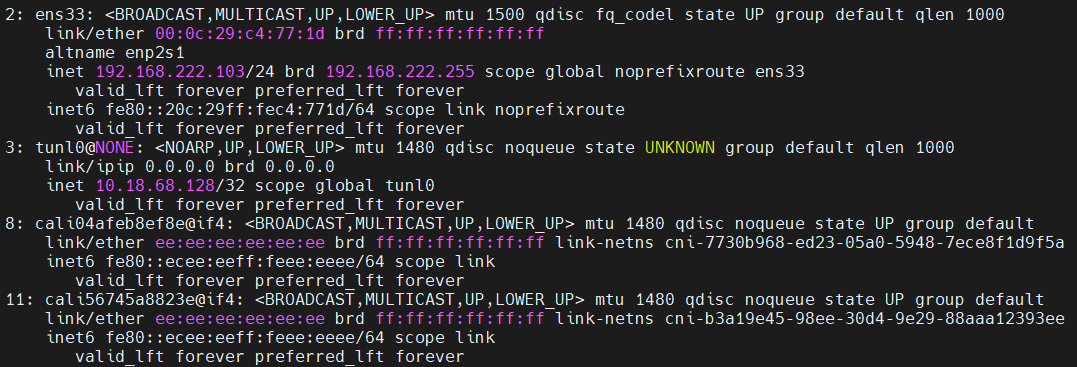 # 2、Service网络 在介绍Service这个api资源对象时,我们已经汇总过Service的几个type:ClusterIP、NodePort、LoadeBalancer,除了这三个还有其它的类型,在本章节我们暂且不去讨论。 这三种类型的Service,LoadBalancer依赖NodePort,而NodePort通常要和ClusterIP一起使用,如果在Service的yaml文件里定义type为LoadBalancer,则它会自动创建NodePort,而NodePort也会自动创建ClusterIP。 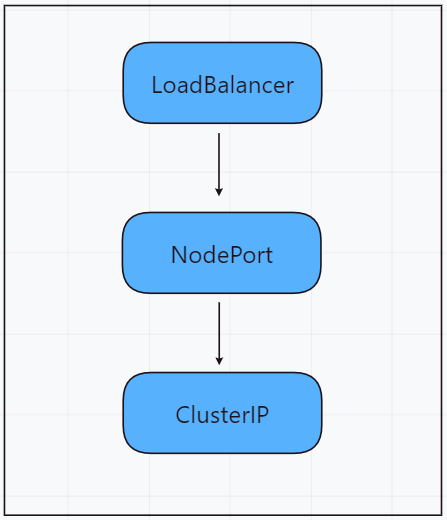 下面,再来演绎一下从Pod到Service的网络变化情况: - 1)单个Pod之间通信 单个Pod和Pod之间通信只能通过Pod的IP和Port来通信,如下图 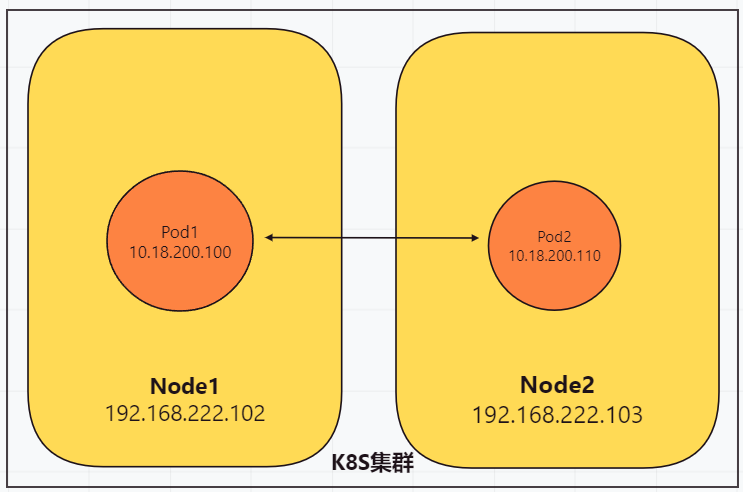 - 2)Pod有多个 当引入了Deployment,并为Pod设置多个副本时,那么提供某一个服务(如Nginx服务)的Pod就不止一个了,此时即使知道了这些Pod的IP,那访问起来也并不方便。所以,这里需要有一个统一入口,其它Pod通过这个统一入口去请求该服务(Nginx)对应的所有Pod。 这时就有了Service这个资源对象,它主要作用就是用来提供统一入口,也就是说只需要一个IP就能访问所有的Pod,而这个入口IP就是ClusterIP,也就是Service的IP。  - 3)外部资源访问内部Pod 有了Service,的确可以很方便为内部的Pod提供入口,但是在集群外面访问这个内部的资源就没办法了。于是,就有了这个NodePort,使用Service的NodePort类型,可以将Service的ClusterIP对应的Port映射到每一个Node的IP上,映射出去的Port范围为30000~32767 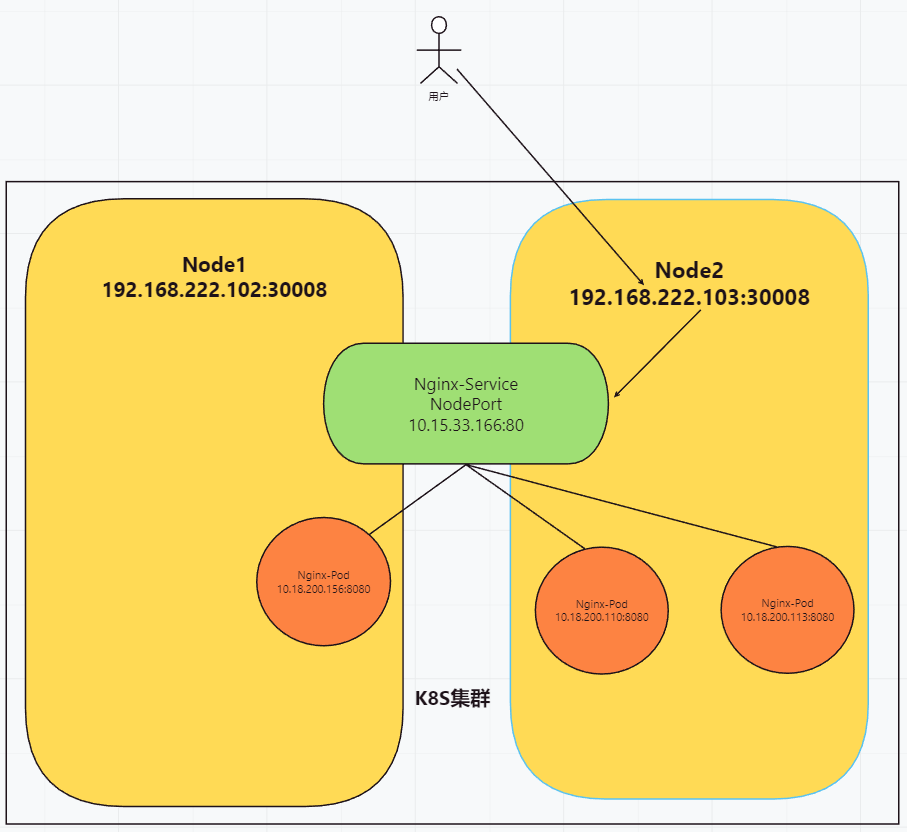 - 4)借助公有云的负载均衡器 使用这个NodePort并不方便,毕竟它带着一个长长的端口号,而且还有一个非常尴尬的问题,就是访问时还得带着Node的IP,如果这个Node挂掉,那么就无法访问此资源,虽然可以通过另外一个Node去访问,但这样太麻烦了!所以,此时的解决方案是:借助三方的负载均衡器,将请求分发到所有的Node上,其底层还是NodePort。 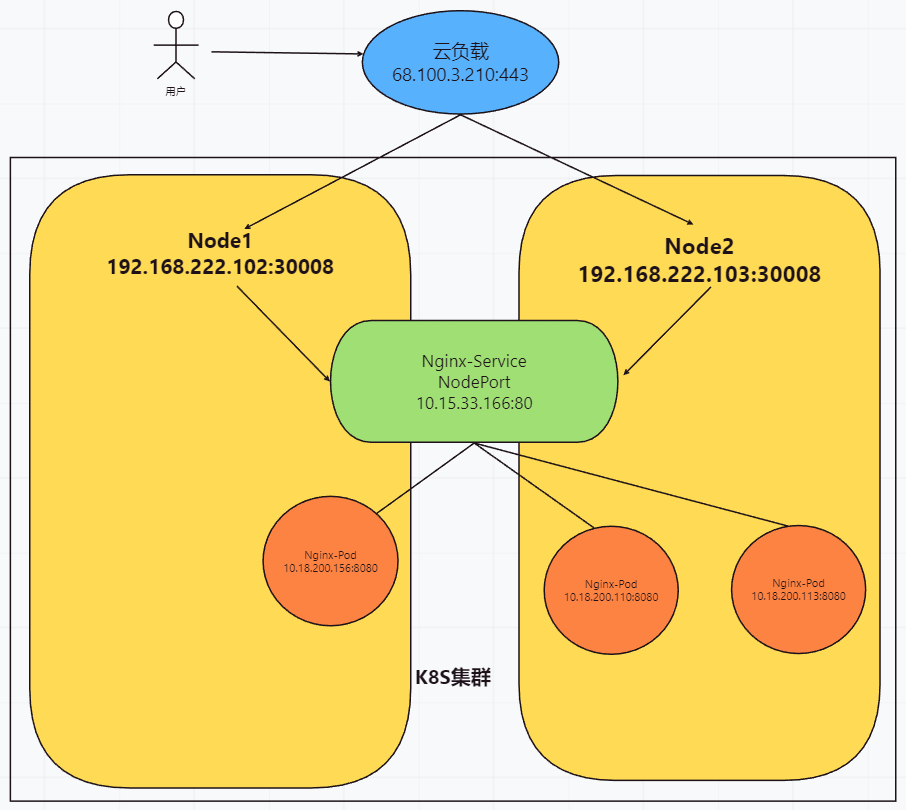 总结:Service为内部Pod的统一入口,内部资源之间可以通过最简单的ClusterIP进行通信,而外部资源访问需要借助NodePort的形式,但是带着长长端口不方便,于是又衍生了LoadBalancer的形式,这种形式需要借助三方的负载均衡器,将请求分发到每一个NodePort上。 # 3、网络插件Calico 参考 https://www.cnblogs.com/goldsunshine/p/10701242.html - 1)Calico是什么 Calico 是一个用于容器、虚拟机和主机的开源网络和网络安全解决方案。它是一个纯三层(L3)解决方案,利用 BGP(Border Gateway Protocol)协议为容器或虚拟机提供 IP 地址,并提供网络安全功能,包括网络策略和加密。 Calico 通过将网络策略应用于标签和选择器,提供了一种简单而强大的方法来保护容器或虚拟机之间的通信,并限制容器或虚拟机可以访问的网络资源。它还支持基于 Kubernetes 和 OpenStack 等平台的网络自动化和集成。 Calico 的另一个重要特点是其可扩展性。它使用了基于 BGP 的路由技术,这使得它能够轻松地扩展到非常大规模的网络中,而不会降低性能。 由于Calico是一种纯三层的方案,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。 - 2)Calico架构 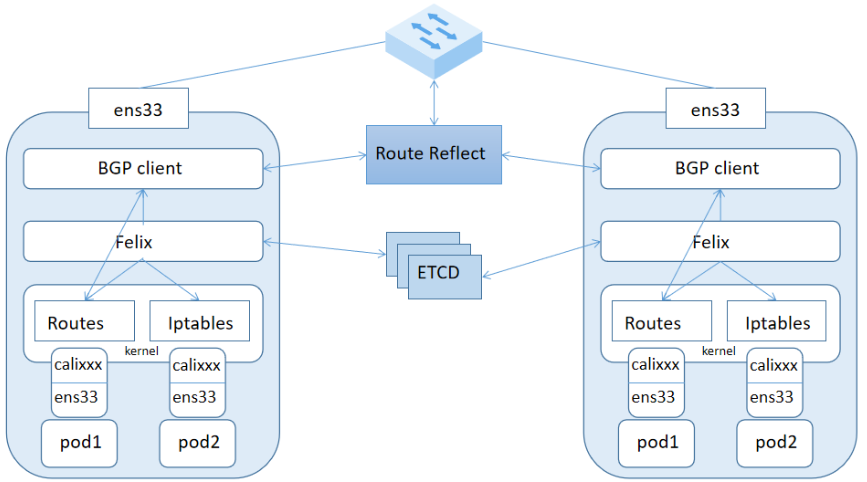 各组件介绍: - Felix:Calico Agent,跑在K8S集群中的每台节点上,主要负责管理和维护该节点上的网络和安全策略,如 网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等; - Etcd:分布式键值存储,用来存储网络元数据、安全策略以及节点的状态信息,确保Calico网络状态的一致性和准确性,可以和K8S的etcd合用; - BGP Client(BIRD):跟Felix一样,每一个节点上都会部署BGP Client,主要负责把Felix写入Kernel的路由信息分发到当前Calico网络,确保各节点间的通信的有效性; - BGP Route Reflector(BIRD): 在大型网络规模中,如果仅仅使用BGP Client 形成mesh全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有BGP Client仅与特定RR节点互联并做路由同步,从而大大减少连接数大规模部署时使用。 关键点: - Felix会定期查询Etcd数据库,从而获取到IP变化信息,比如说用户在这台机器上创建了一个容器,增加了一个IP等。当它发现数据变更后,比如用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。 - BIRD是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。 - 3)calico三种网络工作模式 | 模式 | 说明 | 特点 | | ----- | ------------------------------------------------------------ | ------------------------------------------------------------ | | VXLAN | 封包, 在vxlan设备上将pod发来的数据包源、目的mac替换为本机vxlan网卡和对端节点vxlan网卡的mac。外层udp目的ip地址根据路由和对端vxlan的mac查fdb表获取 | 只要k8s节点间三层互通, 可以跨网段, 对主机网关路由没有特殊要求。各个node节点通过vxlan设备实现基于三层的“二层”互通, 三层即vxlan包封装在udp数据包中, 要求udp在k8s节点间三层可达;二层即vxlan封包的源mac地址和目的mac地址是自己的vxlan设备mac和对端vxlan设备mac。 | | IPIP | 封包,在tunl0设备上将pod发来的数据包的mac层去掉,留下ip层封包。 外层数据包目的ip地址根据路由得到。相当于建立了隧道,把两个本来不通的节点网络通过点对点连接起来。 | 只要k8s节点间三层互通, 可以跨网段, 对主机网关路由没有特殊要求。解包、封包都会造成一定的资源损耗。 适用于互相访问的pod不在同一个网段中、跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。 | | BGP | 边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP | 不用封包解包,通过bgp协议可实现pod网络在主机间的三层可达, k8s节点不跨网段时和flannel的host-gw相似,支持跨网段,跨网段时,需要主机网关路由也充当BGP Speaker能够学习到pod子网路由并实现pod子网路由的转发。总之bgp适用于大规模网络场景。 | - 4)IPIP模式说明 默认网络模式即IPIP模式,在所有节点上查看网卡,会有tunl0网卡。 aminglinux02  aminglinux03  查看路由 aminglinux02 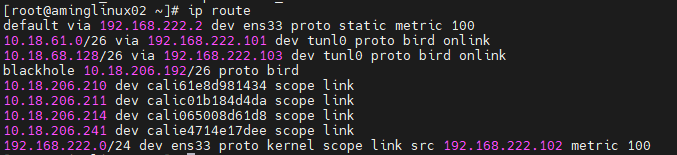 aminglinux03  查看Pod  分析: - ① ng-deploy-7f9cb667d5-v69sn 在aminglinux03上,它的IP为10.18.68.139 - ② 如果68.139要访问另外一个pod ng-deploy-7f9cb667d5-xcmnd,其IP为10.18.206.211 - ③ 它会找路由 10.18.206.192/26 via 192.168.222.102 dev tunl0 proto bird onlink,这条路由对应着aminglinux02的节点IP 192.168.222.102,所以它通过这个IP就能找到10.18.206.211 以上可以说明,IPIP模式就是将节点与节点之间建立了一条隧道,并且建立了对应的路由信息,Pod之间通信时只需要知道目标IP所对应的路由就可以直接访问到对应的节点IP,从而达到对方的Pod。 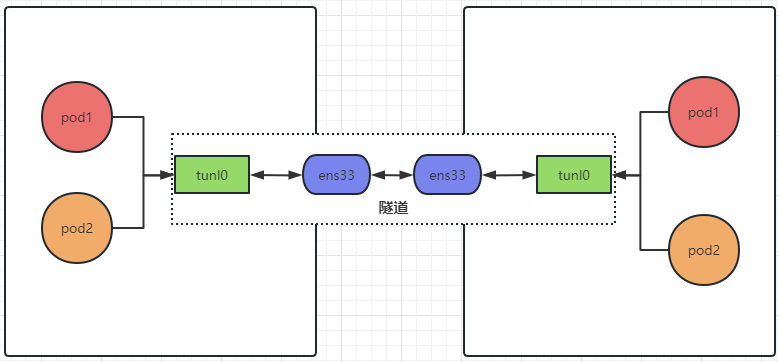 - 5)BGP模式说明 将IPIP模式改为BGP 更改calico-node配置 ``` kubectl edit ds calico-node -n kube-system #会进入vim编辑模式 搜索下面两行 - name: CALICO_IPV4POOL_IPIP value: Always 在它的下面增加: - name: CALICO_AUTODETECTION_METHOD value: interface=eth0 ``` 保存即可生效 更改ippool,保存即可生效 ``` kubectl edit ippool #会进入vim编辑模式 搜索ipipMode 将ipipMode: Always 改为 ipipMode: Never ``` 查看ip,会发现三台机器的tunl0都没有IP地址了  再查看route,使用BGP模式不再显示tunl0  使用IPIP模式时,是有tunl0的  同样还是ng-deploy的两个Pod,对比之前Pod的IP已经发生了变化,因为我重启过机器,但IP段依然是68和206  如果使用BGP模式,68.188访问206.193时,它的路由是10.18.206.192/26 via 192.168.222.102 dev ens33 proto bird 但此时并不需要借助tunl0了,而是直接通过ens33来。 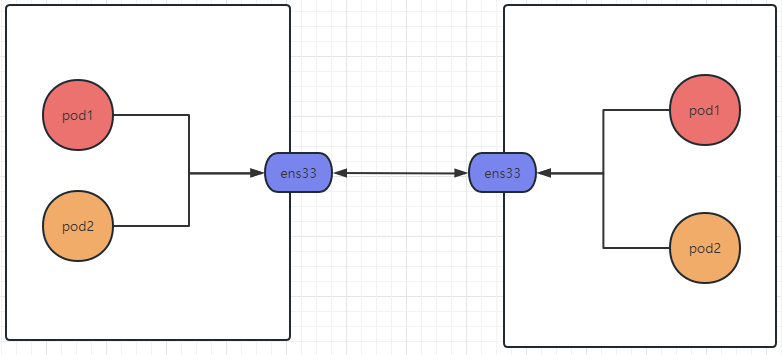 # 4、网络插件Flannel 参考 https://blog.yingchi.io/posts/2020/8/k8s-flannel.html,https://juejin.cn/post/6994825163757846565 - 1)Flannel简介 Flannel也是一个CNI插件,它的功能跟Calico一样,为K8S集群中的Pod提供网络支撑。 Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务。 Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的Pod能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的Pod能够直接通过内网IP通信。简单来说,它的功能是让集群中的不同节点主机创建的Pod都具有全集群唯一的虚拟IP地址。 Flannel实质上是一种“覆盖网络(overlaynetwork)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持udp、vxlan、host-gw、aws-vpc、gce和alloc路由等数据转发方式。 核心关键点: - 网络配置:Flannel 配置存储在etcd中。Flannel节点会从etcd中读取这些配置信息,并根据配置创建和管理网络。 - 子网分配:Flannel会为每个节点分配一个不重叠的子网,以便在节点上运行的Pod可以使用该子网内的IP。这样,集群内的每个Pod都将具有唯一的IP地址。 - 数据包封装与转发:Flannel使用数据包封装技术(例如 VXLAN、UDP 等)将Pod之间的通信封装为跨节点的通信。当一个节点上的Pod 需要与另一个节点上的Pod通信时,源节点上的Flannel程序会将数据包封装,添加上目标子网信息,并将封装后的数据包发送到目标节点。目标节点上的Flannel程序会解封装数据包,并将其转发给目标Pod。 - 兼容性:Flannel可以与k8s中的其他网络插件(如 Calico)一起使用,以实现更复杂的网络功能。这使得Flannel可以很好地适应不同的集群环境和需求。 工作模式: - UDP 模式:使用设备 flannel.0 进行封包解包,不是内核原生支持,频繁地内核态用户态切换,性能非常差,目前官方不建议使用了; - VxLAN 模式:使用 flannel.1 进行封包解包,内核原生支持,性能较强; - host-gw 模式:无需 flannel.1 这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强; - 2)Flannel架构 Flannel在底层实现上要比Calico简单。 Flannel 最主要的两个组件是flanneld跟 flannel.1: - flanneld:控制面,运行在用户态,负责为宿主机分配子网,并监听Etcd,维护宿主机的FDB/ARP跟路由表 - flannel.1:数据面,运行在内核态,作为VTEP,VXLAN 数据包的封包跟解包 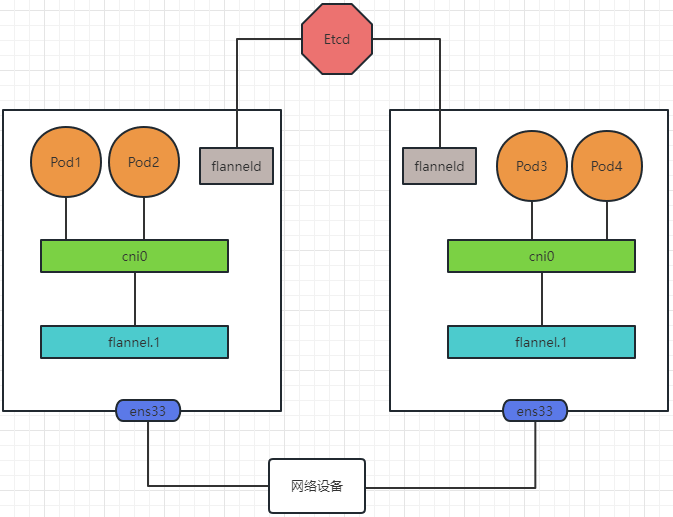 - 3)VxLAN模式: VxLAN的设计思想是: 在现有的三层网络之上,“覆盖”一层虚拟的、由内核VxLAN模块负责维护的二层网络,使得连接在这个VxLAN二层网络上的“主机”(虚拟机或容器都可以),可以像在同一个局域网(LAN)里那样自由通信。 为了能够在二层网络上打通“隧道”,VxLAN会在宿主机上设置一个特殊的网络设备作为“隧道”的两端,叫VTEP:VxLAN Tunnel End Point(虚拟隧道端点) VXLAN是Flannel默认和推荐的模式。当我们使用默认配置安装Flannel时,它会为每个节点分配一个24位子网,并在每个节点上创建两张虚机网卡: cni0 和 flannel.1 。 - cni0 是一个网桥设备,节点上所有的Pod都通过veth pair的形式与cni0相连。 - flannel.1 则是一个VXLAN类型的设备,充当VTEP的角色,实现对VXLAN报文的封包解包。 同一个节点内的Pod之间通信,只需要通过cni0即可,而我们要讨论的重点是跨节点通信。 假设两个节点Node1和Node2,两个节点上分别有两个Pod:PodA和PodB,现在Node1上的PodA要和Node2上的PodB通信,通信过程如下: 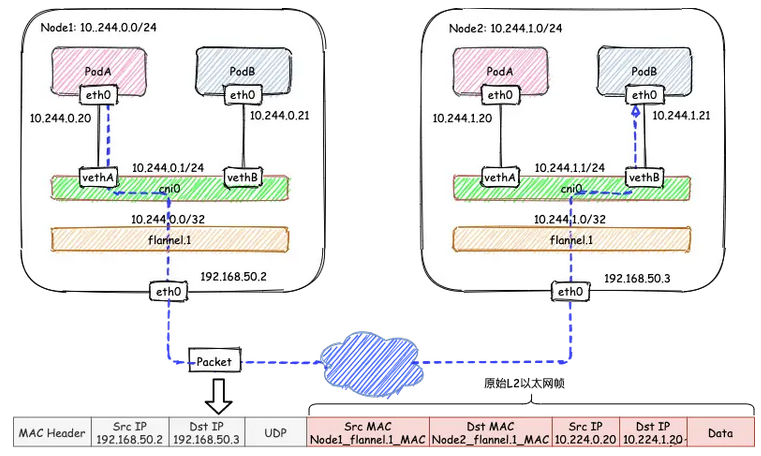 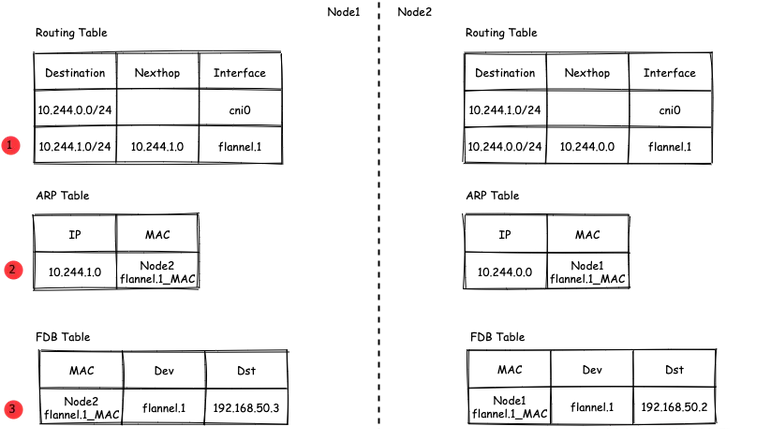 大致概括一下整个过程: - 发送端:在PodA中发起 ping 10.244.1.21 ,ICMP 报文经过 cni0 网桥后交由 flannel.1 设备处理。 Flannel.1 设备是一个VXLAN类型的设备,负责VXLAN封包解包。 因此,在发送端,flannel.1 将原始L2报文封装成VXLAN UDP报文,然后从 eth0 发送。 - 接收端:Node2收到UDP报文,发现是一个VXLAN类型报文,交由 flannel.1 进行解包。根据解包后得到的原始报文中的目的IP,将原始报文经由 cni0 网桥发送给PodB。 路由: Flanneld 从 etcd 中可以获取所有节点的子网情况,以此为依据为各节点配置路由,将属于非本节点的子网IP都路由到 flannel.1 处理,本节点的子网路由到 cni0 网桥处理。 ``` [root@Node1 ~]# ip route 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 # Node1子网为10.224.0.0/24, 本机PodIP都交由cni0处理 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink # Node2子网为10.224.1.0/24,Node2的PodID都交由flannel.1处理 ``` - 4)host-gw网络模式 跟VxLAN不同,host-gw模式下没有flannel.1虚拟网卡,无需建立VxLAN隧道。但它有个缺点,必须要保证各Node在同一个网段。 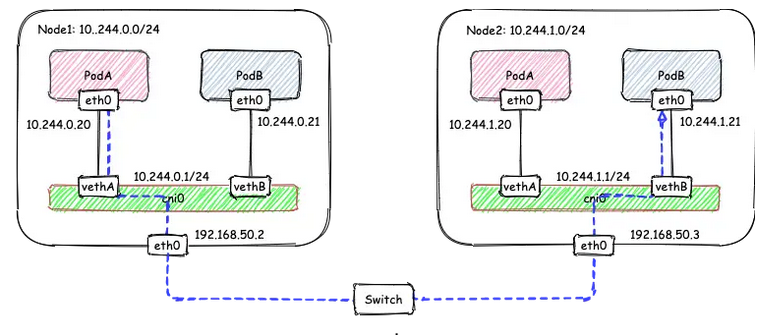 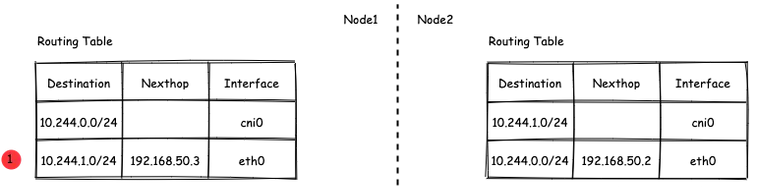 host-gw模式的工作原理,就是将每个Flannel子网的下一跳,设置成了该子网对应的宿主机的 IP 地址,也就是说,宿主机(host)充当了这条容器通信路径的“网关”(Gateway),这正是 host-gw 的含义。 所有的子网和主机的信息,都保存在 Etcd 中,flanneld 只需要 watch 这些数据的变化 ,实时更新路由表就行了。 核心是IP包在封装成桢的时候,使用路由表的“下一跳”设置上的MAC地址,这样可以经过二层网络到达目的宿主机 ``` [root@Node1 ~]# ip r ... 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 10.244.1.0/24 via 192.168.50.3 dev eth0 # Node2子网的下一跳地址指向Node2的public ip。 ... ``` 由于没有封包解包带来的消耗,host-gw是性能最好的。不过一般在云环境下,都不支持使用host-gw的模式,在私有化部署的场景下,可以考虑。 # 5、Kubernetes里的DNS K8s集群内有一个DNS服务: ``` $ kubectl get svc -n kube-system |grep dns kube-dns ClusterIP 10.96.0.10 10.0.1.201 53/UDP,53/TCP,9153/TCP 22d ``` 测试: ``` 在aminglinux01上安装bind-utils,目的是安装dig命令 yum install -y bind-utils 解析外网域名 $ dig @10.96.0.10 www.baidu.com ; <<>> DiG 9.11.36-RedHat-9.11.36-8.el8_8.1 <<>> @10.96.0.10 www.baidu.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53640 ;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 13, ADDITIONAL: 27 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: 8094822d82b894ca (echoed) ;; QUESTION SECTION: ;www.baidu.com. IN A ;; ANSWER SECTION: www.baidu.com. 30 IN CNAME www.a.shifen.com. www.a.shifen.com. 30 IN A 14.119.104.254 www.a.shifen.com. 30 IN A 14.119.104.189 ``` ``` 解析内部域名 $ dig @10.96.0.10 redis-svc.default.svc.cluster.local ; <<>> DiG 9.11.36-RedHat-9.11.36-8.el8_8.1 <<>> @10.96.0.10 redis-svc.default.svc.cluster.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 35621 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: 64a805f1035b42b7 (echoed) ;; QUESTION SECTION: ;redis-svc.default.svc.cluster.local. IN A ;; ANSWER SECTION: redis-svc.default.svc.cluster.local. 30 IN A 10.108.51.179 ;; Query time: 0 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Thu Oct 19 22:39:47 CST 2023 ;; MSG SIZE rcvd: 127 ``` 说明:`redis-svc`为`service name`,`service`完整域名为`service.namespace.svc.cluster.local` 还可以解析Pod,Pod的域名有点特殊,格式为`<pod-ip>.<namespace>.pod.<clusterdomain>`,例如`10-18-206-93.default.pod.cluster.local` 对应的Pod为coredns: ``` $ kubectl get po -n kube-system | grep coredns coredns-5bbd96d687-dpgfn 1/1 Running 1 (67m ago) 10d coredns-5bbd96d687-mjrks 1/1 Running 3 (67m ago) 22d ``` 查看defalut命名空间Pod里的/etc/resolv.conf ``` $ kubectl exec -it redis-sts-0 -- cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 10.96.0.10 options ndots:5 ``` 查看chemex命名空间Pod里的/etc/resolv.conf ``` $ kubectl exec -it ng-deploy-5dc667896b-wb9pz -n chemex -- cat /etc/resolv.conf search chemex.svc.cluster.local svc.cluster.local cluster.local nameserver 10.96.0.10 options ndots:5 ``` 解释: - nameserver: 定义DNS服务器的IP,其实就是kube-dns那个service的IP。 - search: 定义域名的查找后缀规则,查找配置越多,说明域名解析查找匹配次数越多。集群匹配有 default.svc.cluster.local、svc.cluster.local、cluster.local 3个后缀,最多进行8次查询 (IPV4和IPV6查询各四次) 才能得到正确解析结果。不同命名空间,这个参数的值也不同。 - option: 定义域名解析配置文件选项,支持多个KV值。例如该参数设置成ndots:5,说明如果访问的域名字符串内的点字符数量超过ndots值,则认为是完整域名,并被直接解析;如果不足ndots值,则追加search段后缀再进行查询。 > 跨命名空间使用域名是需要补全域名到命名空间部分,例如: kube-dns.kube-system DNS配置 可以通过查看coredns的configmap来获取DNS的配置信息: ``` $ kubectl describe cm coredns -n kube-system Name: coredns Namespace: kube-system Labels: <none> Annotations: <none> Data ==== Corefile: ---- .:53 { errors health { lameduck 5s } ready kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 forward . /etc/resolv.conf { max_concurrent 1000 } cache 30 loop reload loadbalance } BinaryData ==== Events: <none> ``` 说明: - errors:错误信息到标准输出。 - health:CoreDNS自身健康状态报告,默认监听端口8080,一般用来做健康检查。您可以通过http://10.18.206.207:8080/health获取健康状态。(10.18.206.207为coredns其中一个Pod的IP) - ready:CoreDNS插件状态报告,默认监听端口8181,一般用来做可读性检查。可以通过http://10.18.206.207:8181/ready获取可读状态。当所有插件都运行后,ready状态为200。 - kubernetes:CoreDNS kubernetes插件,提供集群内服务解析能力。 - prometheus:CoreDNS自身metrics数据接口。可以通过http://10.15.0.10:9153/metrics获取prometheus格式的监控数据。(10.15.0.10为kube-dns service的IP) - forward(或proxy):将域名查询请求转到预定义的DNS服务器。默认配置中,当域名不在kubernetes域时,将请求转发到预定义的解析器(宿主机的/etc/resolv.conf)中,这是默认配置。 - cache:DNS缓存时长,单位秒。 - loop:环路检测,如果检测到环路,则停止CoreDNS。 - reload:允许自动重新加载已更改的Corefile。编辑ConfigMap配置后,请等待两分钟以使更改生效。 - loadbalance:循环DNS负载均衡器,可以在答案中随机A、AAAA、MX记录的顺序。 # 6、API资源对象ingress 有了Service之后,我们可以访问这个Service的IP(clusterIP)来请求对应的Pod,但是这只能是在集群内部访问。 要想让外部用户访问此资源,可以使用NodePort,即在node节点上暴漏一个端口出来,但是这个非常不灵活。为了解决此问题,K8s引入了一个新的API资源对象Ingress,它是一个七层的负载均衡器,类似于Nginx。 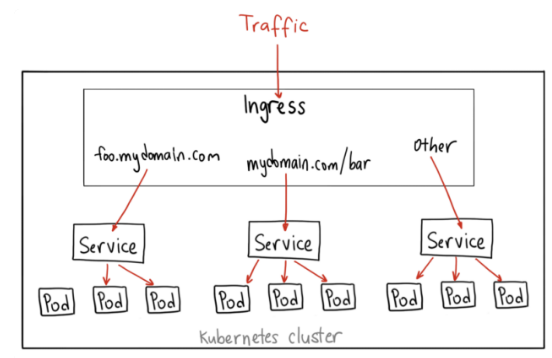 三个概念:Ingress、Ingress Controller、IngressClass - Ingress用来定义具体的路由规则,要实现什么样的访问效果; - Ingress Controller是实现Ingress定义具体规则的工具或者叫做服务,在K8s里就是具体的Pod; - IngressClass是介于Ingress和Ingress Controller之间的一个协调者,它存在的意义在于,当有多个Ingress Controller时,可以让Ingress和Ingress Controller彼此独立,不直接关联,而是通过IngressClass实现关联。 Ingress YAML示例: ``` $ vi mying.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: mying ##ingress名字 spec: ingressClassName: myingc ##定义关联的IngressClass rules: ##定义具体的规则 - host: aminglinux.com ##访问的目标域名 http: paths: - path: / pathType: Exact backend: ##定义后端的service对象 service: name: ngx-svc port: number: 80 ``` 查看ingress ``` $ kubectl get ing $ kubectl describe ing mying ``` IngressClassYAML示例: ``` $ vi myingc.yaml apiVersion: networking.k8s.io/v1 kind: IngressClass metadata: name: myingc spec: controller: nginx.org/ingress-controller ##定义要使用哪个controller ``` 查看ingressClass ``` $ kubectl get ingressclass ``` 安装ingress-controller(使用Nginx官方提供的 https://github.com/nginxinc/kubernetes-ingress) 首先做一下前置工作 ``` $ curl -O 'https://gitee.com/aminglinux/linux_study/raw/master/k8s/ingress.tar.gz' $ tar zxf ingress.tar.gz $ cd ingress $ ./setup.sh ##说明,执行这个脚本会部署几个ingress相关资源,包括namespace、configmap、secrect等 ``` ``` $ vi ingress-controller.yaml apiVersion: apps/v1 kind: Deployment metadata: name: ngx-ing namespace: nginx-ingress spec: replicas: 1 selector: matchLabels: app: ngx-ing template: metadata: labels: app: ngx-ing #annotations: #prometheus.io/scrape: "true" #prometheus.io/port: "9113" #prometheus.io/scheme: http spec: serviceAccountName: nginx-ingress containers: - image: nginx/nginx-ingress:2.2-alpine imagePullPolicy: IfNotPresent name: ngx-ing ports: - name: http containerPort: 80 - name: https containerPort: 443 - name: readiness-port containerPort: 8081 - name: prometheus containerPort: 9113 readinessProbe: httpGet: path: /nginx-ready port: readiness-port periodSeconds: 1 securityContext: allowPrivilegeEscalation: true runAsUser: 101 #nginx capabilities: drop: - ALL add: - NET_BIND_SERVICE env: - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name args: - -ingress-class=myingc - -health-status - -ready-status - -nginx-status - -nginx-configmaps=$(POD_NAMESPACE)/nginx-config - -default-server-tls-secret=$(POD_NAMESPACE)/default-server-secret ``` 应用YAML ``` $ kubectl apply -f ingress-controller.yaml ``` 查看pod、deployment ``` $ kubectl get po -n nginx-ingress $ kubectl get deploy -n nginx-ingress ``` 将ingress对应的pod端口映射到master上临时测试 ``` $ kubectl port-forward -n nginx-ingress ngx-ing-547d6575c7-fhdtt 8888:80 & ``` 测试前,可以修改ng-deploy对应的两个pod里的/usr/share/nginx/html/index.html文件内容,用于区分两个pod 测试 ``` $ curl -x127.0.0.1:8888 aminglinux.com 或者: $ curl -H 'Host:aminglinux.com' http://127.0.0.1:8888 ``` 上面对ingress做端口映射,然后通过其中一个节点的IP来访问ingress只是一种临时方案。那么正常如何做呢?有三种常用的方案: - 1)Deployment+LoadBalancer模式的Service 如果要把ingress部署在公有云,那用这种方式比较合适。用Deployment部署ingress-controller,创建一个type为LoadBalancer的service关联这组pod。 大部分公有云,都会为LoadBalancer的service自动创建一个负载均衡器,通常还绑定了公网地址。 只要把域名解析指向该地址,就实现了集群服务的对外暴露。 - 2)Deployment+NodePort模式的Service 同样用deployment模式部署ingress-controller,并创建对应的服务,但是type为NodePort。这样,ingress就会暴露在集群节点ip的特定端口上。 由于nodeport暴露的端口是随机端口,一般会在前面再搭建一套负载均衡器来转发请求。该方式一般用于宿主机是相对固定的环境ip地址不变的场景。 NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响。 - 3)DaemonSet+HostNetwork+nodeSelector 用DaemonSet结合nodeselector来部署ingress-controller到特定的node上,然后使用HostNetwork直接把该pod与宿主机node的网络打通(如,上面的临时方案kubectl port-forward),直接使用宿主机的80/433端口就能访问服务。 这时,ingress-controller所在的node机器就很类似传统架构的边缘节点,比如机房入口的nginx服务器。该方式整个请求链路最简单,性能相对NodePort模式更好。 缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。比较适合大并发的生产环境使用。 # 7、动态云原生网关 APISIX APISIX也是一种访问K8S集群内部资源的解决方案,相比Ingress,APISIX功能更加强大,可以满足更多复杂应用场景。 - 1)APISIX介绍 Apache APISIX是一个高性能、动态、可扩展的 API 网关,由 Apache 基金会孵化并管理。它基于 Nginx 和 etcd 开发,提供了丰富的流量管理功能,如负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等。APISIX 旨在为微服务和 API 管理提供统一的入口,同时支持各种插件来满足不同的业务需求。 APISIX架构  上图为 APISIX 产品中控制⾯(简称 CP)与数据⾯(简称 DP)的架构⽰意图: - 数据面:数据平⾯⽤于接收并处理调⽤⽅请求,使⽤Lua与Nginx动态控制请求流量。当请求进⼊时,将根据预设路由规则进⾏匹配,匹配到的请求将被⽹关转发⾄对应上游服务。在此过程中,⽹关有能⼒根据预设规则中不同插件的配置,使⽤⼀系列插件对请求从进⼊到离开的各个阶段进⾏操作。例如:请求可能会经过⾝份认证(避免重放攻击、参数篡改等)、请求审计(请求来源信息、上游处理时⻓ 等)、路由处理(根据预设规则获 取最终上游服务地址)、请求转发(⽹关将请求转发⾄上游⽬标节 点)、请求响应(上游处理完成后,⽹关将结果返回给调⽤⽅)等⼏个步骤。 - 控制面: 控制平⾯包含了Admin API与默认配置中⼼ETCD。管理员在访问并操作控制台时,控制台将调⽤Admin API下发配置到ETCD,借助ETCD Watch机制,配置将在⽹关中实时⽣效。例如:管理员可 增加⼀条路由,并配置限速插件,当触发到限速阈值后,⽹关将会暂时阻⽌后续匹配到该路由的请求 进⼊。借助ETCD的Watch机制,当管理员在控制⾯板更新配置后,APISIX将在毫秒级别内通知到各个⽹关节点。。 APISIX采⽤了数据平⾯与控制平⾯分离的架构⽅式,通过配置中⼼接收、下发配置,使 得数据平⾯不会受到控制平⾯影响。配置中⼼默认为 ETCD,但也⽀持 Consul、Nacos、Eureka 等, 可根据您的实际情况进⾏选择。此外,企业⽤⼾只需关注业务本⾝,与业务⽆关的⼤部分功能交给 APISIX 内置插件即可实现,如⾝份验证、性能分析等。 APISIX特点 - ⾼可⽤: APISIX 默认选⽤ ETCD 作为配置中⼼,ETCD 天然⽀持分布式、⾼可⽤,并且在 K8s 等领域有⼤量实践经验,使得 APISIX 可以轻松⽀持毫秒级配置更新、⽀撑数千⽹关节点;⽹关节点⽆状态,可任意扩容或缩容; - 协议转换: ⽀持丰富的协议类型,如 TCP/UDP、Dubbo、MQTT、gRPC、SOAP、WebSocket 等; - 安全防护: 内置多种⾝份验证与安全防护能⼒,如 Basic Auth、JSON Web Token、IP ⿊⽩名单、OAuth 等; - 性能极⾼: APISIX使⽤Radixtree算法实现⾼性能、灵活路由,在 AWS 8 核⼼服务器中,QPS 约为 140K,延迟约 为 0.2 ms; - 全动态能⼒: 修改⽹关配置、增加或修改插件等,⽆需重启⽹关服务即可实时⽣效;⽀持动态加载 SSL 证书; - 扩展能⼒强: 借助灵活的插件机制,可针对内部业务完成功能定制;⽀持⾃定义负载均衡算法与路由算法,不受限于API⽹关实现;通过运⾏时动态执⾏⽤⼾⾃定义函数⽅式来实现Serverless,使⽹关边缘节点更加 灵活; - 治理能⼒丰富: 如故障隔离、熔断降级、限流限速等;在启⽤主动健康检查后,⽹关将⽀持智能跟踪不健康上游节点 的能⼒,并⾃动过滤不健康节点,以提⾼整体服务稳定性。 - 2)APISIX部署 官方文档 : https://apisix.apache.org/zh/docs/apisix/installation-guide/
阿星
2024年1月6日 15:35
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
📢 网站已迁移:
本站内容已迁移至新地址:
zhoumx.net
。
注意:
本网站将不再更新,请尽快访问新站点。
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码