Ops工具
Helm
Helm 包管理工具
Helm进阶
Ansible
Ansible入门
Ansible 常用模块指令
Ansible playbook详解
Vdbench
vdbench基础使用指南
vdbench在ARM服务器上出现共享库aarch64.so问题
GitLab
Gitlab自定义机器人
Gitlab安装和使用
CosBench
Cosbench测试
s3curl
s3curl常用命令大全
S3curl测试
FIO
FIO安装和使用方法
本文档使用 MrDoc 发布
-
+
首页
FIO安装和使用方法
## 0.1 FIO安装和使用方法 ### 0.1.1 rpm安装_X86 1.将上面的rpm包拷贝到测试虚拟机。 2.执行以下命令安装(部分操作系统已经集成libaio,可以忽略安装错误提示)。 rpm –ivh libaio-0.3.107-10.el6.x86_64.rpm rpm –ivh fio-2.0.14-1.el5.rf.x86_64.rpm ### 0.1.2 rpm安装_ARM 1.将上面的rpm包拷贝到测试虚拟机。 2.执行以下命令安装(部分操作系统已经集成libaio,可以忽略安装错误提示)。 rpm –ivh libaio-0.3.109-13.el7.aarch64.rpm rpm –ivh fio-3.7-1.el7.aarch64.rpm ### 0.1.3 源代码安装 1.通过浏览器或者git命令下载fio源代码: [https://github.com/axboe/fio](https://github.com/axboe/fio) git clone [https://github.com/axboe/fio.git](https://github.com/axboe/fio.git) 2.将源代码拷贝到测试虚拟机,然后解压 3.执行以下命令进行编译,编译需要gcc和make工具。 ./configure make make install ### 0.1.4 常用参数 | **类型** | **参数名称** | **解释** | | --- | --- | --- | | IO引擎 | ioengine | 定义fio如何下发IO请求(或者说:定义IO引擎类型),fio支持的IO引擎如下所示:sync, **libaio**, psync, vsync, psyncv, posixaio, solarisaio, windowsaio, mmap, splice, syslet-rw, sg, null, net, netsplice, rdma, cpuio, guasi, falloc, e4defrag, external | | 读写类型 | rw | 定义测试的读写类型,可选的值如下: read, write表示顺序读,顺序写; rw, readwrite表示混合顺序读写; randread, randwrite表示随机读,随机写; randrw表示混合随机读写; 对于读写混合的类型来说,默认的读写比为1:1; | | IO类型 | direct | 定义是否使用Direct IO; 值为0,表示使用buffered IO;值为1,表示使用direct IO; | | IO块大小 | bs | 定义IO的块大小(block size),单位是k, K, m, M等,默认IO块大小为4KB; 如果参数值仅为1个数字,比如bs=4k,则读写IO都是4KB; | | 数据量 | size | 设置IO操作的数据量,除非另外指定了runtime这类参数,fio会将指定大小的数据量全部读/写完成,然后才停止测试。 该参数的值,可以是带单位的数字,比如size=2G,表示读/写的数据量为2GB;也可以是百分数,比如size=20%,表示读/写的数据量占该设备/文件的20%的空间; | | 队列深度 | iodepth | 设置IO队列深度,默认值为1.只对libaio引擎有效。 注意:这里的队列深度是每个线程的队列深度,如果有多个线程测试,意味着每个线程都是这么大的队列深度。Fio总的IO并发数=iodepth * numjobs | | 测试文件 | filename | 设置待测试文件,在Linux下,任何设备都是文件,所以这里的文件既可指代真实的文件,也可以指代待测设备。 | | 测试名称 | name | 设置测试的名称标识,在未指定filename的时候也可以用该参数指定测试的文件名或者设备路径。 | | 进程/线程数 | numjobs | 定义测试的并发数。 注意:各个进程/线程的测试结果默认是分别报告的,如果不想查看各个进程/线程的报告,而想要查看所有进程/线程的统计结果,可以搭配使用参数group_reporting | ### 0.1.5 参数详解 | **参数** | **参数值** | **解释** | | --- | --- | --- | | filename | 设备名或文件名 | 定义测试对象,一般是设备或者文件。 如果想要测试设备/dev/sda,可以设置filename=/dev/sda; 如果想要测试多个设备/dev/sda,/dev/sdb,可以使用冒号将它们分隔开,比如filename=/dev/sda:/dev/sdb | | rw | read, write, rw, readwrite, randread, randwrite, randrw | 定义测试的读写类型: read, write表示顺序读,顺序写; rw, readwrite表示混合顺序读写; randread, randwrite表示随机读,随机写; randrw表示混合随机读写; 对于读写混合的类型来说,默认的读写比为1:1; | | rwmixread | 不超过100的正整数 | 定义在混合读写模式中,读所占的比例.举例来说,如果rwmixread值为10,则表示读写比为10:90; | | rwmixwrite | 不超过100的正整数 | 定义在混合读写模式中,写所占的比例。举例来说,如果rwmixwrite值为10,则表示读写比为90:10; 对于rwmixread和rwmixwrite都设置,并且其和小于100的情况,后设置的参数会覆盖前设置的参数。 | | ioengine | sync, libaio, psync, vsync, psyncv, posixaio, solarisaio, windowsaio, mmap, splice, syslet-rw, sg, null, net, netsplice, rdma, cpuio, guasi, falloc, e4defrag, external | 定义fio如何下发IO请求(或者说:定义IO引擎类型): sync:基本的read, write IO; libaio:Linux原生的异步IO,注意:Linux可能只支持non-buffered IO(设置direct=1或buffered=0)情况下的排队操作; sg:SCSI generic sg v3 io. null:不进行任何数据操作,主要用在学习fio操作或者debug场景; cpuio: 不进行数据操作,而仅仅让CPU跑在指定的负载(需要另外配合cpuload和cpucycle参数使用); external:加载外部的IO引擎文件; 其他IO引擎的介绍参考fio的HOWTO文件; | | direct | 0, 1 | 定义是否使用Direct IO; 值为0,表示使用buffered IO;值为1,表示使用direct IO; | | buffered | 0, 1 | 定义是否使用buffered IO; 值为0,表示使用direct IO;值为1,表示使用buffered IO; 该参数与direct刚好相反,一般建议使用其中之一; | | bs | 带单位的数字 | 定义IO的块大小(block size),单位是k, K, m, M等,默认IO块大小为4KB; 如果参数值仅为1个数字,比如bs=4k,则读写IO都是4KB; 如果参数值为2个数字,比如bs=4k,8k,则表示读IO是4KB,写IO是8KB,trim是8KB; 其他的一些写法: bs=,8K表示读IO使用默认大小(4KB),写IO为8KB; bs=4k,8k,(注意8k后面有个逗号)表示读IO是4KB,写IO是8KB,trim是默认大小(4KB). bs=write:8k,表示每写8K跳8K | | bsrange | 带单位的数字 | bs定义IO块为固定大小,bsrange定义的IO块则为一个区域,测试工具会混合下发大小不同的IO请求; 比如设置bsrange=512-2048,表示fio混合下发从512B到2048B大小的IO,IO块大小的值均为给定最小值的倍数。 Bsrange指定的大小同时适用于读写请求,如果需要设置读写操作使用不同大小,可以参考bs参数,使用逗号将读写请求的IO块分别进行设置。 | | bssplit | | 设置不同大小IO块在测试中所占的比例,参数的格式为:bssplit=blocksize/percentage:blocksize/percentage 举例来说:bssplit=4k/10:64k/50:32k/40表示4KB的IO块占10%,64KB的IO块占50%,32KB的IO块占40%; bssplit=4k/50:1k/:32k/表示4KB的IO块占50%,1KB和32KB的IO块平分剩下的比例,也即25%; bssplit=2k/50:4k/50,4k/90,8k/10表示对读IO来说,2KB和4KB均是50%;对写IO来说,4KB占90%,8KB占10%; | | size | 数字 | 设置IO操作的数据量,除非另外指定了runtime这类参数,fio会将指定大小的数据量全部读/写完成,然后才停止测试。 该参数的值,可以是带单位的数字,比如size=2G,表示读/写的数据量为2GB;也可以是百分数,比如size=20%,表示读/写的数据量占该设备/文件的20%的空间; 除了表示IO操作数据量,size还表示IO操作的范围,与offset配合一起表示读写[offset,offset+size]范围内的数据。 | | runtime | 正整数 | 定义测试时间,以秒为单位。 对于指定的文件/设备,如果在测试时间内完成了读写操作,则会保持相同的负载循环进行读写; | | ramp_time | 正整数 | 定义测试的热身时间,以秒为单位。 热身时间不计入测试统计; | | numjobs | 正整数 | 定义测试的并发数。 各个进程/线程的测试结果默认是分别报告的,如果不想查看各个进程/线程的报告,而想要查看所有进程/线程的统计结果,可以搭配使用参数group_reporting | | group_reporting | NA | 对于测试并发数大于1的情况,如果想要将所有进程/线程的测试结果进行统计,输出总的测试结果,而不是各自单独输出,可以使用此参数。参考参数numjobs。 | | iodepth | 正整数 | 设置IO队列深度,更大的队列深度意味着并发提高,默认值为1. 需要注意的是:设置的队列深度不一定能够达到,可以从fio的输出结果中检查iodepth实际达到的值。 | | iodepth_batch | 正整数 | 一次提交的IO请求个数。 | | iodepth_batch_complete | 正整数 | 更低的iodepth_batch_complete一般意味着更低的IO延时。 | | iodepth_low | 正整数 | 设置IO队列深度的低水位,随着IO请求被处理,队列里的IO逐渐减少,当达到低水位时,fio工具会重新下发IO请求; | | invalidate | 0, 1 | 设置在测试开前,是否将buffer/page cache失效,默认为失效。 | | output | 文件名 | 将测试输出保存到文件里,而不是默认的屏幕上; | | ioscheduler | cfq, deadline, noop, anticipatory | 设置设备的IO调度算法 | | refill_buffers | NA | 没有参数值,该参数指定了每次提交IO后,都重复填充IO buffer。 | | sync | 0, 1 | Use sync io for buffered writes. For the majority of the io engines, this means using O_SYNC. | | overwrite | 0, 1 | 对写操作而言,设置文件是否可以覆盖,默认为可覆盖。 | | fsync | 正整数 | 对写操作而言,设置多少次写操作后,进行数据同步。 | | rate_iops | 正整数 | 限制单个线程的IOPS数为指定的数字。 举例来说:-numjobs=10, -rate_iops=100,表示起10个线程,每个线程的IOPS限制为100; 注意:对于混合读写来说,该参数的限制 | | rate_iops_min | 正整数 | 与rate_iops不同的是,设置rate_iops_min时,当被测设备达不到该参数指定的最小IOPS需求时,fio退出测试。 | | thinktime | 正整数 | 设置当一个IO完成后,等待多少时间再下发另一个IO,单位为微秒。 一般用于模拟应用等待、处理事务等。 | | thinktime_spin | 正整数 | 仅当thinktime参数设置时,本参数才有效。 用于模拟应用在等待数据过程中spin的时间,此时应用仍然消耗CPU,当spin的时间过去,thinktime的剩余时间将进入sleep。 | | thinktime_blocks | 正整数 | 仅当thinktime参数设置时,本参数才有效。 用于设置进程在进入thinktime之前,发出多少个IO请求。默认值为1。 | ### 0.1.6 命令行测试方法 #### 0.1.6.1 测试裸盘性能 **fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=5G -numjobs=10 -runtime=1000 -group_reporting -name=mytest** 说明: filename=/dev/sdb1 测试文件名称,通常选择需要测试的盘的data目录,是没有文件系统的裸盘。 direct=1 测试过程绕过机器自带的buffer。使测试结果更真实。 rw=randwrite 测试随机写的I/O rw=randrw 测试随机写和读的I/O bs=16k 单次io的块文件大小为16k bsrange=512-2048 同上,提定数据块的大小范围 size=5g 本次的测试文件大小为5g,以每次4k的io进行测试。 numjobs=10 本次的测试线程为10,jobs和CPU的core数相等时,性能较好,但是通常32个job即可测试出最大性能 runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止。 ioengine=psync io引擎使用pync方式,也可以使用libaio rwmixwrite=30 在混合读写的模式下,写占30% group_reporting 关于显示结果的,汇总每个进程的信息。 此外 lockmem=1g 只使用1g内存进行测试。 zero_buffers 用0初始化系统buffer。 nrfiles=8 每个进程生成文件的数量。 **顺序读:** fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest **随机写:** fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest **顺序写:** fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest **混合随机读写:** fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop #### 0.1.6.1.1 测试文件系统 **fio -directory=/data -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=5G -numjobs=10 -runtime=1000 -group_reporting -name=mytest** 说明: directory=/data 测试的路径,为已经做过文件系统的空间这种方式,通常是将一块裸盘,进行分区、格式化,然后挂载到此目录,然后进行测试,本文档不单独提供分区、格式化、挂载目录等操作步骤。 ### 0.1.7 FIO结果分析 Fio测试完成后会打印测试结果,我们主要关注IOPS、带宽和时延,对应的值如下图: 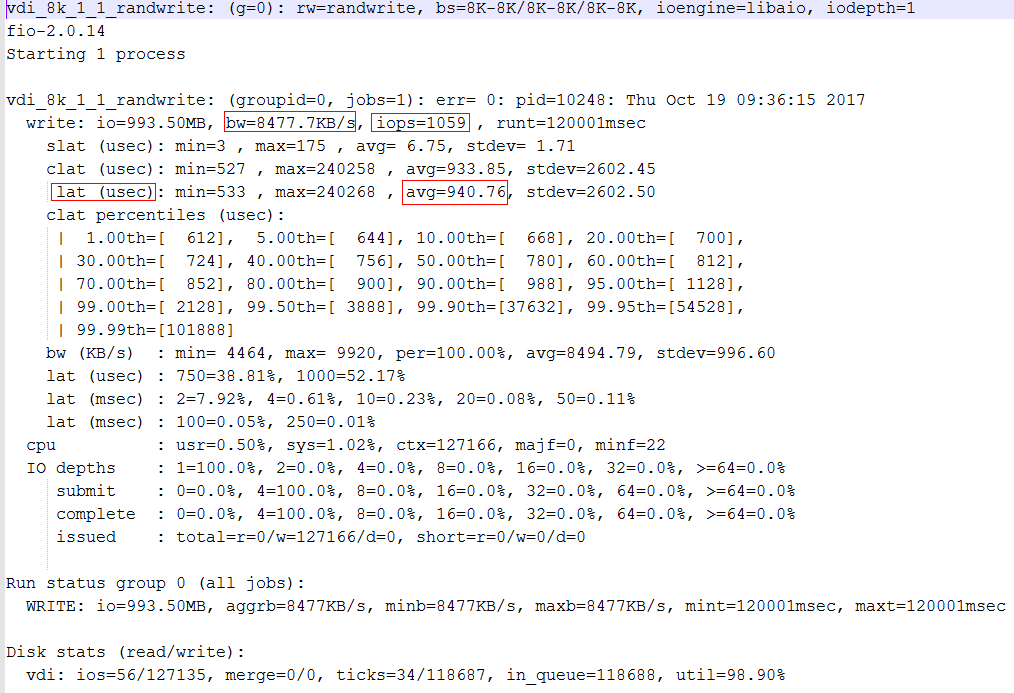
阿星
2024年1月21日 22:33
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
📢 网站已迁移:
本站内容已迁移至新地址:
zhoumx.net
。
注意:
本网站将不再更新,请尽快访问新站点。
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码