云原生
Kubernetes基础
容器技术介绍
Docker快速入门
Containerd快速入门
K8S主要资源罗列
认识YAML
API资源对象
Kubernetes安全掌控
Kubernetes网络
Kubernetes高级调度
Kubernetes 存储
Kubernetes集群维护
Skywalking全链路监控
ConfigMap&Secret场景应用
Kubernetes基础概念及核心组件
水平自动扩容和缩容HPA
Jenkins
k8s中部署jenkins并利用master-slave模式实现CICD
Jenkins构建过程中常见问题排查与解决
Jenkins部署在k8s集群之外使用动态slave模式
Jenkins基于Helm的应用发布
Jenkins Pipeline语法
EFKStack
EFK日志平台部署管理
海量数据下的EFK架构优化升级
基于Loki的日志收集系统
Ingress
基于Kubernetes的Ingress-Nginx解决方案
Ingress-Nginx高级配置
使用 Ingress-Nginx 进行灰度(金丝雀)发布
Ingress-nginx优化配置
APM
Skywalking全链路监控
基于Helm部署Skywalking
应用接入Skywalking
服务网格
Istio
基于Istio的微服务可观察性
基于Istio的微服务Gateway实战
Kubernetes高可用集群部署
Kuberntes部署MetalLB负载均衡器
Ceph
使用cephadm部署ceph集群
使用Rook部署Ceph存储集群
openstack
glance上传镜像失败
mariadb运行不起来
创建域和项目错误_1
创建域和项目错误_2
安装计算节点
时钟源
网络创建失败
本文档使用 MrDoc 发布
-
+
首页
容器技术介绍
# 1、什么是容器 容器是一个工具,可以将程序、文件、配置等打包,运行在任意计算机上; 可以实现一次打包,多次使用,方便快捷,一条命令就可以运行; Docker和容器不能划等号,Docker只是一个容器管理工具,而真正的容器技术是LXC(Linux Container);  容器就像上图中的集装箱,每一个集装箱都是一个完整的应用; # 2、容器与虚拟化对比 容器类似于虚拟化,但和虚拟化有本质区别 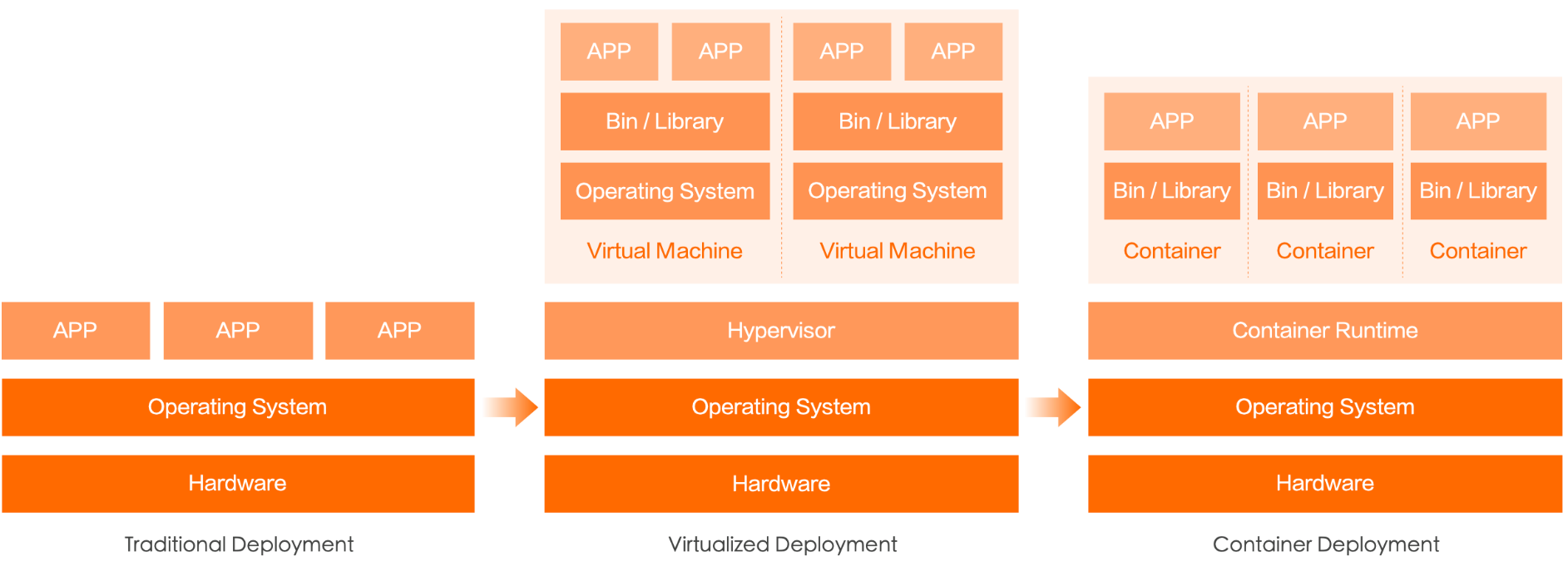 虚拟化会使用虚拟机监控程序模拟硬件,从而使多个操作系统能够并行运行。但这不如容器轻便。 容器和宿主机共享内核等资源,而虚拟化是直接虚拟出来;相较于虚拟机,Linux容器在运行时所占用的资源更少,使用的是标准接口(启动、停止、环境变量等),并会与应用隔离开。 Linux容器在本机操作系统上运行,与所有容器共享该操作系统,因此应用和服务能够保持轻巧,并行化快速运行。 Linux容器镜像提供了可移植性和版本控制,确保能够在开发人员的笔记本电脑上运行的应用,同样也能在生产环境中正常运行。 * VM 模拟整个计算机,包括虚拟化硬件、OS、用户模式及其自身的内核模式。 VM 非常灵活,可为应用程序提供广泛的支持;但是,VM 往往比较大,会消耗主机资源。 * 容器基于主机操作系统内核构建,并包含打包的应用的独立用户模式进程。 这有助于使容器轻量化且快速启动。 # 3、容器基本概念 - LXC: 是Linux Contain的缩写,就是Linux容器,是一个基于Linux内核功能特性实现轻量级虚拟化的技术。注意,Docker/Podman等容器技术,都是在LXC基础之上开发的三方工具。 LXC可以在操作系统层次上为进程提供虚拟的执行环境,一个虚拟的执行环境就是一个容器。可以为容器绑定特定的cpu和memory节点,分配特定比例的cpu时间、IO时间,限制可以使用的内存大小(包括内存和是swap空间),提供device访问控制,提供独立的namespace(网络、pid、ipc、mnt、uts)。 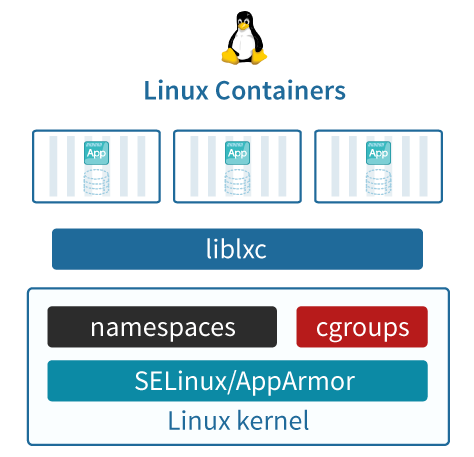 - 容器的隔离 容器有效地将操作系统管理的资源划分到独立的组中,并把各个独立的组进行隔离,可以让各自的组占用独立的资源,完成自己独立的任务。 因为容器最终执行的命令也是调用统一的os api来实现,是基于整个os来实现的,所以不需要单独操作系统的编译系统、执行解释器,一切工作都是基于os 的基础上来完成的。 容器通过提供一种创建和进入容器的方式,让程序像跑在独立机器那样在容器中运行,并且相互之间不影响,而且还可以共享底层的资源。 - 容器的共享 容器提供环境隔离的前提下,还提供了资源共享的机制,所以容器比真正kvm 虚拟机的资源要节省许多; # 4、容器的核心技术 ## 4.1 chroot 创建一个虚拟的根目录文件系统,其实质还是调用底层的文件系统,不过是建立一个虚拟的、可以跟其它容器的虚拟文件系统相互隔离、但共享底层的文件系统。 每个容器都具有独立的文件系统,单个容器内对文件系统进行增删改查不会影响到其他容器。 ## 4.2 namespace : Namespace(命名空间)是一种隔离机制,用于将全局系统资源划分为多个独立的逻辑部分,以便不同的进程或应用程序之间能够使用不同的资源名称或标识符,避免冲突和混淆。 Linux的Namespace是一种由内核直接提供的全局资源封装,它是内核针对进程设计的访问隔离机制。 进程在一个独立的 Linux Namespace中会认为它拥有这台 Linux 主机上的一切资源,不仅文件系统是独立的,还有着独立的 PID 编号(比如拥有自己的 0 号进程,即系统初始化的进程)、UID/GID 编号(比如拥有自己独立的 root 用户)、网络(比如完全独立的 IP 地址、网络栈、防火墙等设置),等等。 事实上,Linux的Namespace设计最早只针对文件系统,但到了后来,要求系统隔离其他访问操作的呼声就愈发强烈,从 2006 年起,内核陆续添加了UTS、IPC等命名空间隔离,后续Linux命名空间支持了以下八种资源的隔离(内核的官网Kernel.org上仍然只列出了前六种,从 Linux 的 Man 命令能查到全部八种): | 命名空间 | 说明 | 内核版本 | | ------------------------------------------------------------ | ---------------------------------------------- | -------- | | Mount | 文件系统隔离 | 2.4.19 | | UTS | 主机的Hostname、Domain names | 2.6.19 | | IPC | 隔离进程间通信的渠道 | 2.6.19 | | PID | 隔离进程编号,无法看到其它命名空间的PID | 2.6.24 | | Network | 隔离网络资源,如网卡、网络栈、IP地址、端口 | 2.6.29 | | User | 隔离用户和用户组 | 3.8 | | Cgroup | 隔离Cgroup信息,进程有自己的Cgroup的根目录视图 | 4.6 | | Time | 隔离系统时间 | 5.6 | | 容器技术的产生就是因为Linux的Namespace的存在,在Linux系统里要想运行多个容器,那么容器与宿主机之间、容器与容器之间必须要做到相互隔离,它们会认为自己拥有了整个硬件以及软件资源。可以说如果没有Namespace技术,就不会有容器技术。 | | | ## 4.3 cgroups: Cgroups是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制。比如给容器A分配4颗CPU,8G 内存,那这个容器最多用这么多的资源。如果内存超过8G ,会启动swap,效率降低,也可能会被调度系统给kill掉。 Cgroups全称是Control Groups,Cgroup为每种可以控制的资源都定义了一个子系统。它的子系统有: * cpu子系统:限制进程的cpu使用率; * cpuacct子系统:统计Cgroups中进程cpu使用报告; * cpuset子系统:为Cgroups中的进程分配单独的cpu节点或者内存节点; * memory子系统:限制进程的memory使用量; * blkio子系统:限制进程的块设备io; * devices子系统:控制进程能够访问某些设备; * net_cls子系统:标记cgroups中进程的网络数据包,然后可以使用tc模块(traffic control)对数据包进行控制; * freezer子系统:挂起或者恢复cgroups中的进程; 还有其它的,具体可以通过这个命令查看: ``` ls /sys/fs/cgroup/ ``` **Cgroups是如何做限制** 在cpu子系统下创建目录 ``` cd /sys/fs/cgroup/cpu mkdir container ls container #下面会自动生成诸多文件,这些文件就是资源限制文件 cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.rt_period_us cpu.stat cgroup.procs cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.rt_runtime_us notify_on_release cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us cpu.shares tasks ``` 执行一个耗费cpu资源的进程 ``` [root@master01 container]# while : ; do : ; done & #这样会做一个死循环进程,会导致cpu达到100% [1] 24639 [root@master01 container]# top top - 18:28:11 up 1:59, 2 users, load average: 0.88, 0.51, 0.35 Tasks: 330 total, 2 running, 328 sleeping, 0 stopped, 0 zombie %Cpu(s): 13.7 us, 0.9 sy, 0.0 ni, 84.8 id, 0.1 wa, 0.4 hi, 0.2 si, 0.0 st MiB Mem : 16016.1 total, 13101.7 free, 1295.2 used, 1619.2 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 14440.1 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24639 root 20 0 225024 656 0 R 99.7 0.0 1:32.26 bash ``` 查看quota_us和period_us ``` [root@master01 container]# cat cpu.cfs_quota_us ##-1表示未做任何限制 -1 [root@master01 container]# cat cpu.cfs_period_us ##这里的100000为us,也就是100ms 100000 ``` 两个值组合在一起,就达到了一个限制的作用,修改上面两个值 ``` echo 30000 > cpu.cfs_quota_us ##改为30ms,意思是100ms内,将cpu的限额最多给到30ms,也就是30% ``` 再将上面的死循环进程id,做一下限制 ``` [root@master01 container]# echo 24639 > tasks ``` 再次用top查看cpu使用率,会发现最终会使用30%,这就是Cgoups的限制。 ``` [root@master01 container]# top top - 18:29:56 up 2:00, 2 users, load average: 0.68, 0.59, 0.40 Tasks: 329 total, 2 running, 327 sleeping, 0 stopped, 0 zombie %Cpu(s): 4.8 us, 0.9 sy, 0.0 ni, 93.4 id, 0.3 wa, 0.4 hi, 0.2 si, 0.0 st MiB Mem : 16016.1 total, 13080.9 free, 1315.7 used, 1619.5 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 14419.6 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24639 root 20 0 225024 656 0 R 29.8 0.0 2:40.74 bash ``` #### 总结 Linux Cgroups的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。 而对于Docker等Linux容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的PID填写到对应控制组的tasks文件中就可以了。 而至于在这些控制组下面的资源文件里填上什么值,就靠用户启动容器时的参数指定了。 # 5、为什么要使用容器技术 - 节省运维成本: 使用主流的容器编排和管理工具(如,K8s),可以大大降低企业的运维成本,因为K8s本身集成了高可用、负载均衡、监控、自动修复等诸多功能,一旦上线,几乎不用花额外的运维成本。 - 节约资源: 相比于虚拟机,容器可以使用更少的资源来运行同样的应用程序或服务。这意味着可以在一台主机上同时运行更多的应用程序或服务,从而节约成本和资源。 - 提高部署效率: 容器可以快速地启动和停止,容器镜像可以被快速地构建和部署。这使得开发者和 IT 运维人员可以更快地部署新应用程序或服务。 - 提高应用程序的可移植性: 容器可以在不同的环境中运行,包括本地开发环境、测试环境和生产环境。这使得应用程序在不同的环境中都能够正常运行,从而提高了应用程序的可移植性。 - 改善系统安全性: 容器可以提供隔离和安全性,它们使用 Linux 内核的命名空间和控制组技术来隔离应用程序和服务之间的资源。这意味着即使一个容器受到攻击,也不会影响到其他容器或主机。 # 6、相关工具(具有代表性的) 1. Docker Docker是一个开源的应用容器引擎,基于go语言开发并遵循了apache2.0协议开源。 Docker诞生于2013年,它的出现推动了容器技术发展的步伐,使其突飞猛进、日新月异。可以说,没有Docker,就没有后续的K8s、云原生。 学K8s之前,需要先学Docker,学会其镜像、容器、卷等概念。 2. Podman Podman是一个开源项目,在Github上已有12k+Star,可在大多数Linux平台上使用。 Podman是一个无守护进程的容器引擎,用于在Linux系统上开发、管理和运行OCI(Open Container Initiative)容器和容器镜像。 Podman提供了一个与Docker兼容的命令行工具,可以简单地为docker命令取别名为podman即可使用,所以说如果你会Docker的话可以轻松上手Podman。 目前在RHEL系统里默认自带了Podman,说明红帽公司更倾向于Podman。 3. Kubernetes(K8s) 简单来说,Kubernetes 就是一个生产级别的容器编排平台和集群管理系统,不仅能够创建、调度容器,还能够监控、管理服务器,它凝聚了 Google 等大公司和开源社区的集体智慧,从而让中小型公司也可以具备轻松运维海量计算节点——也就是“云计算”的能力。 作为世界上最大的搜索引擎,Google 拥有数量庞大的服务器集群,为了提高资源利用率和部署运维效率,它专门开发了一个集群应用管理系统,代号 Borg,在底层支持整个公司的运转。 2014 年,Google 内部系统要“升级换代”,从原来的 Borg 切换到 Omega,于是按照惯例,Google 会发表公开论文。在发论文的同时,把 C++ 开发的 Borg 系统用 Go 语言重写并开源,于是 Kubernetes 就这样诞生了。 由于 Kubernetes 背后有 Borg 系统十多年生产环境经验的支持,技术底蕴深厚,理论水平也非常高,一经推出就引起了轰动。 然后在 2015 年,Google 又联合 Linux 基金会成立了 CNCF(Cloud Native Computing Foundation,云原生基金会),并把 Kubernetes 捐献出来作为种子项目。 有了 Google 和 Linux 这两大家族的保驾护航,再加上宽容开放的社区,作为 CNCF 的“头把交椅”,Kubernetes 旗下很快就汇集了众多行业精英,仅用了两年的时间就打败了同期的竞争对手 Apache Mesos 和 Docker Swarm,成为了这个领域的唯一霸主。 # 7、k8s废弃Docker - 1)Kubernetes与Docker Docker是最早出现的那批容器引擎工具,所以它最早占领了市场。Kubernetes主要用来做容器编排,用来管理容器集群,是一个平台。 Kubernetes要想去控制容器,就得借助容器引擎,在早期的Kubernetes版本里,除了选择Docker作为容器引擎外,没更好的选择。所以早期的Kubernetes和Docker深深地绑定了在一起。 由于Docker可以在没有Kubernetes的情况下使用,而Kubernetes必须要有容器运行时(Docker引擎)才能进行编排。 这对于Kubernetes来说,绝对是一个非常大的隐患,这相当于是将自己命根子交给了别人,如果哪天Docker翻脸了,Kubernetes必然损失巨大。 好在,Kubernetes发展比Docker更加迅猛,势头远远盖过了Docker,Kubernetes终于有资格自己决定做一些事情了。 - 2)CRI K8s在1.5版本里,引入了一个新的接口标准:CRI(Container Runtime Interface),它主要用来规定如何调用容器运行时来管理容器和镜像,但这个接口标准和之前的Docker调用标准有不少差异,所以两者完全不兼容。这意味着,K8s可以撇开Docker,使用其它容器运行时(如rkt)。 由于Docker用户非常庞大,K8s也意识到了直接不兼容Docker会有许多不确定风险,当时,K8s用了一个临时方案,在K8s和Docker中间开发了一个Dockershim,主要用来将Docker的接口标准转换成CRI标准。 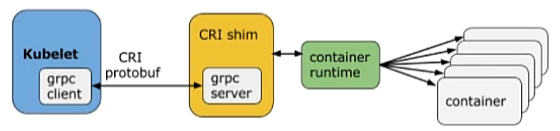 - 3)Containerd Docker意识到Kubernetes的改变,为了迎合Kubernetes,将Docker Engine拆分成多个模块,其中Docker Daemon部分也就是说Containerd捐献给了CNCF。 所以,Containerd实际上是Docker引擎拆出来的一个模块。 Containerd 作为 CNCF 的托管项目,自然是要符合 CRI 标准的。但当时的Docker 出于自己诸多原因的考虑,它只是在 Docker Engine 里调用了 containerd,外部的接口仍然保持不变,也就是说还不与 CRI 兼容。 在当时的Kubernetes版本里,有两种方法调用容器: 第一种是用 CRI 调用 dockershim,然后 dockershim 调用 Docker,Docker 再走 containerd 去操作容器。 第二种是用 CRI 直接调用 containerd 去操作容器。 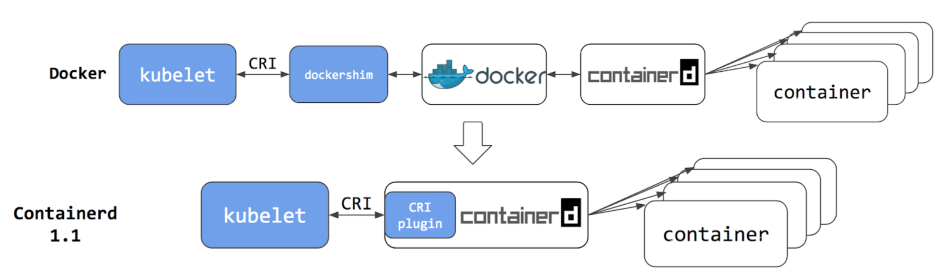 很明显,第一种方法多了两层调用,性能明显不如第二种方法。所以Kubernetes决定将dockershim移除,所以也就不能直接使用Docker了,在外界看来就像是Kubernetes弃用了Docker。 - 4)弃用dockershim 2020年Kubernetes发布1.20版本时,对外声明将在后续版本里(实际上是在22年的1.24版本里)移除dockershim,也就是取消对Docker的支持。当时,众多吃瓜群众理解错了意思,认为成了Kubernetes弃用Docker。它实际上只是“弃用了 dockershim”这个小组件,也就是说把 dockershim 移出了 kubelet,并不是“弃用了 Docker”这个软件产品。 这个举措对Kubernetes和 Docker 来说都不会有什么太大的影响,因为他们两个都早已经把下层都改成了开源的 containerd,原来的 Docker 镜像和容器仍然会正常运行,唯一的变化就是 Kubernetes绕过了 Docker,直接调用 Docker 内部的 containerd 而已。 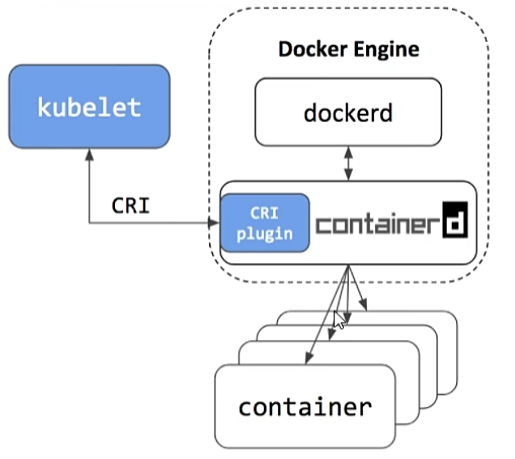 - 5)Kubernetes移除dockershim后对Docker的影响 虽然现在 Kubernetes 不再默认绑定 Docker,但 Docker 还是能够以其他的形式与 Kubernetes 共存的。 首先,因为容器镜像格式已经被标准化了(OCI 规范,Open Container Initiative),Docker 镜像仍然可以在 Kubernetes 里正常使用,原来的开发测试、CI/CD 流程都不需要改动,我们仍然可以拉取 Docker Hub 上的镜像,或者编写 Dockerfile 来打包应用。 其次,Docker 是一个完整的软件产品线,不止是 containerd,它还包括了镜像构建、分发、测试等许多服务,甚至在 Docker Desktop 里还内置了 Kubernetes。单就容器开发的便利性来讲,Docker 还是暂时难以被替代的,广大云原生开发者可以在这个熟悉的环境里继续工作,利用 Docker 来开发运行在 Kubernetes 里的应用。 再次,虽然 Kubernetes 已经不再包含 dockershim,但 Docker 公司却把这部分代码接管了过来,另建了一个叫 cri-dockerd的项目,作用也是一样的,把 Docker Engine 适配成 CRI 接口,这样 kubelet 就又可以通过它来操作 Docker 了,就仿佛是一切从未发生过。 综合来看,Docker 虽然在容器编排战争里落败,被 Kubernetes 排挤到了角落,但它仍然具有强韧的生命力,多年来积累的众多忠实用户和数量庞大的应用镜像是它的最大资本和后盾,足以支持它在另一条不与 Kubernetes 正面交锋的道路上走下去。而对于我们这些初学者来说,Docker 方便易用,具有完善的工具链和友好的交互界面,市面上很难找到能够与它媲美的软件了,应该说是入门学习容器技术和云原生的“不二之选”。
阿星
2024年1月6日 13:42
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
📢 网站已迁移:
本站内容已迁移至新地址:
zhoumx.net
。
注意:
本网站将不再更新,请尽快访问新站点。
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码